CUDA 介绍
本篇博客介绍CUDA的实现,包括物理和逻辑,内存结构等。
GPU物理层
NVidia GPU的流处理器(Stream Multiprocessors, SM)是GPU种非常重要的部分,GPU的并行性是由SM决定的。 以Fermi架构为例,主要组成部分如下:
- CUDA cores,执行单元
- Shared Memory/L1Cache,共享内存和一级Cache
- Register File
- Load/Store Units
- Special Function Units: 特殊函数单元(SFU),用以计算log/exp,sin/cos,rcp/rsqrt的单精度近似值;
- Warp Scheduler:一个线程束调度器。
CUDA基本概念
函数限定符
__device__ :声明某函数在设备上执行,只能从设备中调用
__global__
:声明某函数为内核(kernel)函数,在设备上执行,只能从宿主中调用
__host__ :host声明某函数在宿主上执行,只能从宿主中调用
变量类型限定符
__constant__ 限定符与 __device__
结合使用,声明变量:
驻留在常量内存空间中,具有应用程序的生命期,可通过运行时库被网格的所有线程访问,也可被宿主访问。
__shared__ 限定符可以与 __device__
结合使用,声明变量:
驻留在线程块的共享内存空间中,具有块的生命期,仅可被块内的所有线程访问。
逻辑层
CUDA为了方便编程,提出了 kernel 、 thread
、 block 、 grid 、 warp 概念。 -
kernel : 是CUDA
C扩展C语言函数定义出来的函数,它可以被N个CUDA线程调用N次。 -
thread :
GPU程序执行的最小单位,每个线程拥有自己的程序计数器和状态寄存器,并且用自己的数据执行指令。
每个线程可以有自己独立的 指令寄存器 、
寄存器状态 、 独立的执行路径 。
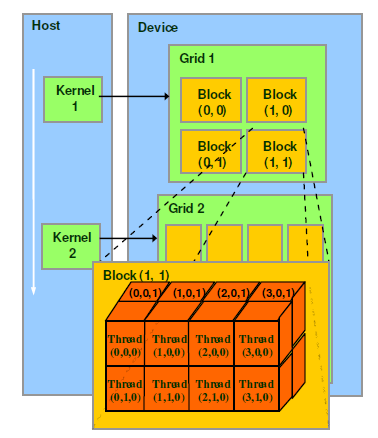
block:一个block由3维空间的thread组成,同一个block中的thread可以同步,也可以通过shared memory通信。grid:一个grid再由3维空间的block组成。warp:GPU执行 程序的调度单位,目前cuda的一个warp由32个线程组成。warp包含32个线程,用以协调把指令分发到执行单元,是调度和运行的基本单位。warp中的所有threads并行执行相同的指令。 一个warp只能分配到一个SM运行, 一个SM可以同时允许多个warp执行。
thread 、 block 、 grid 、
kernel 的关系图:
内存层次
register
GPU 寄存器提供了线程快速存取地址,每个寄存器大小为32位,寄存器数量有限。
| Compute capability | #registers per thread |
|---|---|
| 1.x | 128 |
| 2.x | 63 |
| 3.x | 63 |
| 3.5 | 255 |
Kernel中的局部(简单类型)变量第一选择是被分配到寄存器中。
比如, kernel1 中的变量 a[ARRAY_SIZE]
优化为寄存器。
代码出处:CUDA之编程中线程分配的数组在register中还是local
memory中?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18__global__ void kernel1(float *buf) {
float a[ARRAY_SIZE];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = 0; i < 5; ++i) {
a[i] = buf[tid];
}
float sum = 0.f;
for (int i = 0; i < 5; ++i) {
//static indexing
sum += a[i];
}
buf[tid] = sum;
}
local memory
local memory 或者称为 “thread-local global
memory”,属于片下内存,因此访问速度慢,带宽小。
由于寄存器数量有限,当寄存器耗尽后,线程中数据将被存储到local
memory。
如果每个线程中使用了过多的寄存器(known as register
spilling),或声明了大型结构体或大数组,或编译器无法确定数组大小(Dynamic
Indexing),线程的私有数据就会被分配到local memory中。
local memory 是每个线程私有。
tips:
在声明局部变量时,尽量使变量可以分配到register。如:
1
unsigned int mt[3];
1
unsigned int mt0, mt1, mt2;
编译器会将自动变量存放入local memory中。 更多内容参考 https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#device-memory-accesses
In
a CUDA kernel, how do I store an array in “local thread memory”?
shared memory
shared memory 按照线程块(block)划分,
其上的数据可以为同一 block 中的所有线程共享。 每个
warp 的 shared memory 大小是 64KB
, 这个和 L1 cache 共用。、 按照 16KB L1 / 48KB shared 或者
48KB L1 / 16KB shared 划分。 ([PixelVault])
同一个线程块中的线程可以通过共享内存互相通信,在逻辑上同一个线程块中的所有线程同时执行,但是在物理上,同一个线程块中的所有线程并不是同时执行的,所以同一个线程块中的线程并不是同时执行结束的。
共享内存可能会导致线程之间的竞争:多个线程同时访问某个数据。CUDA提供了线程块内的同步,保证同一个线程块中的线程在下一步执行前都完成了上一步的执行。但是线程块之间无法同步。
global memory
存储器和编程逻辑之间的关系如下表:
| 存储器 | 位置 | 访问权限 | 生存周期 |
|---|---|---|---|
| register | GPU 片内 | Device 读写 | thread |
| local memory | 板载显存 | Device 读写 | thread |
| shared memory | GPU 片内 | Device 读写 | block |
| Constant memory | 板载显存 | host 读写, Device 读 | host分配释放 |
| Texture memory | 板载显存 | host 读写, Device 读 | host分配释放 |
| Global memory | 板载显存 | host 读写, Device 读写 | host分配释放 |
| Host memory | host 内存 | host 读写 | host分配释放 |
| Pinened memory | host 内存 | host 读写 | host分配释放 |
driver API
不同于运行时 runtime API , Driver API
提供了GPU更底层的访问控制,用于后向兼容GPU驱动。Driver API实现在动态库
cuda.so中,函数名称以 cu 开头。
CUDA中能够访问到的对象如下表。
| Object | Handle | Description |
|---|---|---|
| Device | CUdevice | CUDA-enabled device |
| Context | CUcontext | Roughly equivalent to a CPU process |
| Module | CUmodule | Roughly equivalent to a dynamic library |
| Function | CUfunction | Kernel |
| Heap memory | CUdeviceptr | Pointer to device memory |
| CUDA array | CUarray | Opaque container for one-dimensional or two-dimensional data on the device, readable via texture or surface references |
| Texture reference | CUtexref | Object that describes how to interpret texture memory data |
| Surface reference | CUsurfref | Object that describes how to read or write CUDA arrays |
| Event | CUevent | Object that describes a CUDA event |
在调用Driver API 前需要调用 cuInit()
来初始化。然后必须创建一个CUDA上下文
Context,该Context附加到特定设备并使其成为当前调用主机线程的当前上下文。
在CUDA Context内部,内核通过主机代码显式加载为PTX或二进制对象。 因此,用C编写的内核必须单独编译为PTX或二进制对象。 但是 任何想要在未来的设备架构上兼容运行的应用程序都必须加载PTX,而不是二进制代码。 这是因为二进制代码是体系结构特定的,因此可能与未来的体系结构存在着不兼容性,而PTX代码在加载时由设备驱动程序编译为二进制代码。
Driver API的例子: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62int main()
{
int N = ...;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
// Initialize input vectors
...
// Initialize
cuInit(0);
// Get number of devices supporting CUDA
int deviceCount = 0;
cuDeviceGetCount(&deviceCount);
if (deviceCount == 0) {
printf("There is no device supporting CUDA.\n");
exit (0);
}
// Get handle for device 0
CUdevice cuDevice;
cuDeviceGet(&cuDevice, 0);
// Create context
CUcontext cuContext;
cuCtxCreate(&cuContext, 0, cuDevice);
// Create module from binary file
CUmodule cuModule;
cuModuleLoad(&cuModule, "VecAdd.ptx");
// Allocate vectors in device memory
CUdeviceptr d_A;
cuMemAlloc(&d_A, size);
CUdeviceptr d_B;
cuMemAlloc(&d_B, size);
CUdeviceptr d_C;
cuMemAlloc(&d_C, size);
// Copy vectors from host memory to device memory
cuMemcpyHtoD(d_A, h_A, size);
cuMemcpyHtoD(d_B, h_B, size);
// Get function handle from module
CUfunction vecAdd;
cuModuleGetFunction(&vecAdd, cuModule, "VecAdd");
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid =
(N + threadsPerBlock - 1) / threadsPerBlock;
void* args[] = { &d_A, &d_B, &d_C, &N };
cuLaunchKernel(vecAdd,
blocksPerGrid, 1, 1, threadsPerBlock, 1, 1,
0, 0, args, 0);
...
}
CUDA 的上下文也类似于CPU 进程的上下文,一般情况下,它是管理CUDA程序中所有对象生命周期的容器。这些对象包括:
所有分配内存(线性设备内存,host内存,和CUDA arrays)
Modules,类似于动态链接库,以.cubin和.ptx结尾
CUDA streams,管理执行单元的并发性
CUDA events
texture和surface引用
kernel里面使用到的本地内存(设备内存)
用于调试、分析和同步的内部资源
用于分页复制的固定缓冲区CUDA runtime(软件层的库)不提供API直接访问CUDA context,而是通过延迟初始化(deferred initialization)来创建context。 具体意思是,不涉及到context内容的API,Driver不会主动创建context,比如cudaGetDeviceCount等函数。否则,例如申请内存等API就可以显式的控制初始化,即调用cudaFree(0)。尤其是在第一次调用一个改变驱动状态的函数时会自动默认创建一个上下文环境,如cudaMalloc() 默认在 GPU 0 上创建上下文。 CUDA runtime将context和device的概念合并了,即在一个GPU上操作可看成在一个context下。因而cuda runtime提供的函数如cudaDeviceSynchronize()对应于Driver API的cuCtxSynchronize()。
应用可以通过驱动API来访问当前context的栈。与context相关的操作,都是以cuCtxXXXX()的形式作为driver API实现。
GPU设备驱动通过设备驱动程序为应用程序提供多个上下文环境,就可以使单个CUDA应用程序使用多个设备。 但同一时刻只能有一个上下文环境处于活动状态,如果需要操作多个设备时,需要用cudaSetDevice()切换上下文环境。
上下文中包含的关键抽象是其地址空间:即可用于分配线性设备内存或映射锁页主机内存的私有虚拟内存地址集。这些地址是在每个上下文中唯一的。不同上下文的相同地址可能有效也可能无效,并且当然不会解析到相同的内存位置,除非做出特殊规定。 CUDA上下文的地址空间是独立的,与CUDA主机代码使用的CPU地址空间不同。
当context被销毁,里面分配的资源也都被销毁,一个context内分配的资源不能被其他的context使用。在Driver API中,每一个cpu线程都有一个current context的栈,新建的context就入栈。 针对每一个线程只能有一个出栈变成可使用的current context,而这个游离的context可以转移到另一个cpu线程,通过函数cuCtxPushCurrent/cuCtxPopCurrent来实现。 current context堆栈的另一个好处是能够从不同的CPU线程驱动给定的CUDA上下文。 使用驱动程序API的应用程序可以通过使用cuCtxPopCurrent()弹出上下文,然后从另一个线程调用cuCtxPushCurrent(),将CUDA上下文“迁移”到其他CPU线程。