NVIDIA GPU 硬件介绍
本文介绍NVIDIA GPU的硬件组成,为全面了解GPU的架构和逆向GPU结构,全虚拟化GPU提供硬件背景知识。
nVidia GPU Model
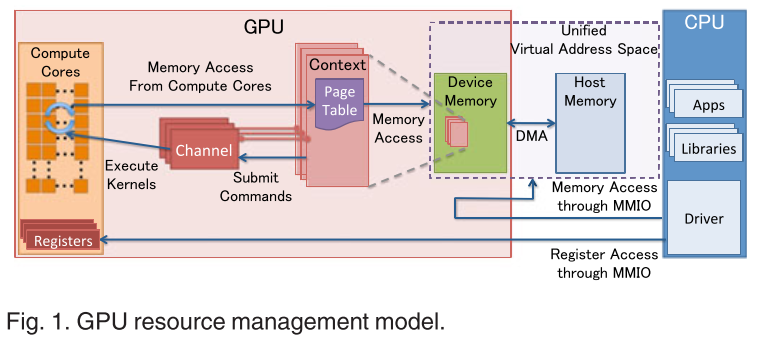
从上述图可以看出组成GPU的几个重要组成: + MMIO: +
CPU与GPU的交流就是通过MMIO进行的。 +
DMA传输大量的数据就是通过MMIO进行命令控制的 +
I/O端口可用于间接访问MMIO区域,像Nouveau等开源软件从来不访问它 + GPU
context + GPU context代表了GPU计算的状态 + 在GPU上拥有自己的虚拟地址 +
在GPU上可以共存多种context + GPU channel + 任何命令都是由CPU发出 +
命令流(command stream)被提交到硬件单元,也就是GPU channel + 每个GPU
channel关联一个context,而一个GPU context可以有多个GPU channel。 +
每个GPU context 包含相关channel的 GPU channel descriptors 。 每个
descriptor 都是 GPU 内存中的一个对象。 + 每个 GPU channel descriptor
存储了 channel 的设置,其中就包括 page table 。 + 在每个 GPU channel
中,在GPU内存中分配了唯一的命令缓存,这通过MMIO对CPU可见。 + GPU context
switching 和命令执行都在GPU硬件内部调度。 + GPU Page Table + GPU context
在虚拟基地空间由页表隔离其他的 context 。 +
GPU的页表隔离CPU页表,位于GPU内存中。 + GPU 页表的物理地址位于 GPU
channel descriptor 中。 + GPU 页表不仅仅将
GPU虚拟地址转换成GPU内存的物理地址,也可以转换成CPU的物理地址。因此,GPU页表可以将GPU虚拟地址和CPU内存地址统一到GPU统一虚拟地址空间来。
+ PCIe BAR + GPU 设备通过PCIe总线接入到主机上。 base address
registers(BARs) 是 MMIO的窗口,在GPU启动时候配置。 +
GPU的控制寄存器和内存都映射到了BARs中。 +
GPU设备内存通过映射的MMIO窗口去配置GPU和访问GPU内存。 + PFIFO Engine +
PFIFO是GPU命令提交通过的一个特殊的部件 +
PFIFO维护了一些独立命令队列,也就是 channel + 此命令队列是
ring buffer,有 PUT 和 GET
的指针。 + 所有访问 channel 控制区域的执行指令都被 PFIFO
拦截下来。 + GPU 驱动使用 channel descriptor 来存储相关的
channel 设定。 + PFIFO 将读取的命令转交给 PGRAPH engine +
BO + Buffer Object (bo),内存的一块(block),能够用于存储 texture, a
render target, shader code等等。 + nouveau和gdev经常使用BO
其他概念:
+ VRAM - Video RAM + fence - Piece of
memory which is updated by GPU when it reaches some step in command
stream
+ PCI memory - An area of system memory that can be
accessed by direct-memory access from the GPU
+ PGRAPH engine - The engine of the GPU that actually
performs graphics operations like blitting and drawing triangles. It can
be programmed by directly writing to its registers in MMIO space or by
feeding commands through the PFIFO engine.
+ PRAMIN - instance memory area
+ GART - Graphics address remapping table or
graphics aperture remapping table ,或者 graphics
translation table (GTT) ,是 Accelerated Graphics Port (AGP) 和
PCIe显卡 使用的 I/O memory management unit(IOMMU) 。
GART 允许显卡通过 textures,
polygon meshes 和其他载入的数据 DMA到主机内存。
PCIe 应用程序编程
在 PCIe 配置空间里,0x10开始后面有6个32位的BAR寄存器,BAR寄存器中存储的数据是表示PCIe设备在PCIe地址空间中的基地址,注意这里不是表示PCIE设备内存在CPU内存中的映射地址,关于这两者的关系如下。
BAR寄存器存储的总线地址,应用程序是不能直接利用的,应用程序首先要做的就是读出BAR寄存器的值,然后用
mmap 函数建立应用程序内存空间和总线地址空间的映射关系。
这样应用程序往 PCIe 设备内存读写数据的时候,直接利用 PCIe
设备映射到应用程序中的内存地址即可。
读写 PCI 设备的具体代码参考Simple program to read &
write to a pci device from userspace。 利用的是 sysfs
设备文件 和 mmap() 函数。
首先找出PCI 映射的文件,比如在
/sys/devices/pci0000\:00\ 中。
查找 PCIe 的设备文件也可以到
/sys/bus/pci_express/devices/ 中。
查找 NVIDIA 的驱动: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46ll /sys/devices/pci0000\:00/0000\:00\:01.0/0000\:01\:00.0/
总用量 0
drwxr-xr-x 12 root root 0 7月 5 11:46 ./
drwxr-xr-x 8 root root 0 7月 5 11:46 ../
-r--r--r-- 1 root root 4096 7月 3 16:19 boot_vga
-rw-r--r-- 1 root root 4096 7月 5 11:55 broken_parity_status
-r--r--r-- 1 root root 4096 7月 3 16:19 class
-rw-r--r-- 1 root root 4096 7月 3 16:19 config
-r--r--r-- 1 root root 4096 7月 5 11:55 consistent_dma_mask_bits
-rw-r--r-- 1 root root 4096 7月 5 11:55 d3cold_allowed
-r--r--r-- 1 root root 4096 7月 3 16:19 device
-r--r--r-- 1 root root 4096 7月 5 11:55 dma_mask_bits
lrwxrwxrwx 1 root root 0 7月 3 16:19 driver -> ../../../../bus/pci/drivers/nvidia/
-rw-r--r-- 1 root root 4096 7月 5 11:55 driver_override
drwxr-xr-x 4 root root 0 7月 3 16:19 drm/
-rw-r--r-- 1 root root 4096 7月 3 16:30 enable
drwxr-xr-x 4 root root 0 7月 3 16:19 i2c-0/
drwxr-xr-x 4 root root 0 7月 3 16:19 i2c-1/
drwxr-xr-x 4 root root 0 7月 3 16:19 i2c-2/
drwxr-xr-x 4 root root 0 7月 3 16:19 i2c-3/
drwxr-xr-x 4 root root 0 7月 3 16:19 i2c-4/
drwxr-xr-x 4 root root 0 7月 3 16:19 i2c-5/
drwxr-xr-x 4 root root 0 7月 3 16:19 i2c-6/
-r--r--r-- 1 root root 4096 7月 3 16:21 irq
-r--r--r-- 1 root root 4096 7月 5 11:55 local_cpulist
-r--r--r-- 1 root root 4096 7月 3 16:19 local_cpus
-r--r--r-- 1 root root 4096 7月 5 11:49 modalias
-rw-r--r-- 1 root root 4096 7月 5 11:55 msi_bus
drwxr-xr-x 2 root root 0 7月 4 08:38 msi_irqs/
-rw-r--r-- 1 root root 4096 7月 3 16:19 numa_node
drwxr-xr-x 2 root root 0 7月 5 11:55 power/
--w--w---- 1 root root 4096 7月 5 11:55 remove
--w--w---- 1 root root 4096 7月 5 11:55 rescan
-r--r--r-- 1 root root 4096 7月 3 16:19 resource
-rw------- 1 root root 16777216 7月 3 16:30 resource0
-rw------- 1 root root 134217728 7月 5 11:55 resource1
-rw------- 1 root root 134217728 7月 5 11:55 resource1_wc
-rw------- 1 root root 33554432 7月 5 11:55 resource3
-rw------- 1 root root 33554432 7月 5 11:55 resource3_wc
-rw------- 1 root root 128 7月 5 11:55 resource5
-rw------- 1 root root 524288 7月 3 16:19 rom
lrwxrwxrwx 1 root root 0 7月 3 16:19 subsystem -> ../../../../bus/pci/
-r--r--r-- 1 root root 4096 7月 3 16:19 subsystem_device
-r--r--r-- 1 root root 4096 7月 3 16:19 subsystem_vendor
-rw-r--r-- 1 root root 4096 7月 3 16:19 uevent
-r--r--r-- 1 root root 4096 7月 3 16:19 vendor1
ll /sys/class/drm/card0/device
此显卡为 GeForce GTX TITAN Black, 设备ID为
1 | $ cat device |
目前推测:
BAR0、BAR1、BAR3、BAR5
分别对应 resource0、 resource1 、
resource3 、 resource5 。
不过各个文件的代表意思,可以通过 Accessing PCI device resources through sysfs 了解下。
PCI/PCIE/AGP bus interface and card management logic
PCI BARs and other means of accessing the GPU
GPU的当前形式是PCI express设备。除PCI配置空间和VGA兼容I/O端口外,NVIDIA GPU还通过PCI向系统公开以下基址寄存器(BAR)。
- BAR0
Memory-mapped I/O (MMIO) registers - BAR1
Device memory windows. - BAR2/3
Complementary space of BAR1. - BAR5
I/O port. - BAR6
PCI ROM.
Nvidia GPU BARs, IO ports, and memory areas
nvidia GPU通过PCI对外暴露了下面区域:
- PCI 配置空间 / PCIe 扩展配置空间
- MMIO 寄存器: BAR0 - 内存范围 0x1000000 字节或更多
通过MMIO寄存器控制所有引擎。
地址通过PCI BAR 0 来设置。 BAR使用32位地址,是非预取内存。
其中寄存器是32位的,读取时需要32位对齐。 在 NV1A+ 系列显卡中,寄存器的字节序列由PMC中的 开关(switch)控制。从显卡内部访问总是小端序列。
PMC是显卡master controller,尤其重要的MMIO空间的子区域,区域范围在 0x000000 到 0x000fff 之间,包括GPU id信息, Big Red Switch, master 中断控制。
- VRAM (on-board 内存): BAR1 -内存范围 0x1000000 字节或者更多
这是映射了VRAM的预取内存。在PCIe卡上,使用64位地址;而在PCI卡上,使用32位地址。 BAR的大小取决于显卡类型。而且BAR的大小独立于真实的VRAM大小。这意味着NV30+显卡不可能通过BAR映射出所有的显卡内存。 - NV3 非直接内存访问IO端口: BAR2 - 0x100 字节的IO端口空间
这IO端口范围用于非直接访问BAR0 或 BAR1 通过 实模式代码。这在NV3上有。
- RAMIN: BAR2 或 BAR3 - 内存 0x1000000 字节或更多,取决于显卡类型。
RAMIN是在pre-G80显卡上VRAM末端特殊的区域,保存着各种控制结构体。 RAMIN开始于VRAM的末端,地址向相反的方向增长。因此需要特殊的映射访问它。
pre-NV40显卡限制其大小为1MB,为NV3调整了BAR0 或 BAR1 中的映射。 NV40+ 允许更大的 RAMIN 地址。
- BAR 5: G80非直接内存访问
查看方法
通过 lspci 命令查看本机PCI设备列表。
01:00.0 VGA compatible controller: NVIDIA Corporation GK110B [GeForce GTX TITAN Black] (rev a1)
查看此PCI设备的ID。
1 | sudo lspci -s 01:00.0 -n |
01:00.0 0300: 10de:100c (rev a1) 即,设备ID是
100c,而厂商ID是10de。 查看详细的信息:
1 | sudo lspci -v -s 01:00.0 |
01:00.0 VGA compatible controller: NVIDIA Corporation GK110B [GeForce GTX TITAN Black] (rev a1) (prog-if 00 [VGA controller])
Subsystem: NVIDIA Corporation GK110B [GeForce GTX TITAN Black]
Flags: bus master, fast devsel, latency 0, IRQ 37
Memory at f2000000 (32-bit, non-prefetchable) [size=16M]
Memory at e8000000 (64-bit, prefetchable) [size=128M]
Memory at f0000000 (64-bit, prefetchable) [size=32M]
I/O ports at e000 [size=128]
[virtual] Expansion ROM at f3000000 [disabled] [size=512K]
Capabilities: <access denied>
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nouveau, nvidia_384_drm, nvidia_384BAR0: 0xf2000000 (MMIO registers) BAR1 and BAR2: 0xe8000000 BAR3 and BAR4: 0xf0000000 BAR5: 0xe000 (I/O port)
参考 1. PCI Express I/O System 2. lspci
PFIFO
PFIFO
用于收集用户发送的命令并将其传送到执行单元。大致分成三部分:
+ PFIFO cache: 以FIFO的队列形式存储要执行的GPU命令。 + PFIFO
pusher:搜集用户输入的命令并将其存入cache中。
共有两种模式:PIO和DMA模式。 PIO模式中,用户直接通过USER MMIO
区域写入命令。
DMA模式中,PFIFO从内存的buffer中读命令,称为pushbuffer的内存,而USER
MMIO 区域仅用于控制pushbuffer 读取。
+ PFIFO puller:从cache中取命令,并将其送往执行单元。
但是 envytools
FIFO overview 将PFIFO 大致分为4部分,多了
PFIFO switcher 。
- PFIFO pusher: 收集用户的command并存入 PFIFO CACHE
- PFIFO CACHE: command队列,等待被 PFIFO puller执行
- PFIFO puller: 执行 command,并将command传给合适的engine或者driver
- PFIFO switcher: 它勾选出通道的时间片,并保存/恢复PFIFO寄存器和RAMFC存储器之间的通道状态。
channel
channel 是PFIFO最核心的概念,它是单独的命令流。
channel是上下文切换并且独立的。
channel的组成:
- channel mode: PIO [NV1:GF100], DMA [NV4:GF100], or IB [G80-]
- PFIFO DMA pusher state [DMA and IB channels only]
- PFIFO CACHE state: the commands already accepted but not yet executed
- PFIFO puller state
- RAMFC: VRAM内存一部分,保存了当前尚未激活的channel上述组成部分,对用户不可见。
- RAMHT [pre-GF100 only]: channel可以使用的 "objects" 哈希表。 objects通过任意的32位句柄handle来区分,可以是DMA对象,engine对象。在G80以前的显卡,独立的对象能够在channel之间共享。
- vspace [G80+ only]: 页表,描述了执行channel中命令的engine可见的虚拟内存。 多个channel可以共享一个 vspace。
- engine-specific state
channel mode
channel的模式决定了提交命令到channel的方式。
PIO模式只在GF100以前的显卡上存在,并且将方法直接戳(poking)到通道控制区域。此方法很慢,不推荐使用。
G80引入了IB模式。
IB模式是DMA模式的修改版本,它不是从内存中跟随单个命令流,而是能够将多个内存区域的部分组合成单个命令流
- 允许使用早期直接从内存中提取参数的命令构造提交的命令。
(搞不懂?)
GF100重构了整个PFIFO,最多可同时执行3个通道,并引入了新的DMA数据包格式。
为了节省PFIFO每个channel上下文,使用了 RAMFC
内存结构体。 PFIFO cache 每次只能对单一的channel设置。 从NV50
开始,PFIFO上下文在做切换时候会保存到memory中。
当pusher把command插入新的channel时,channel会切换。
当puller传递命令时,puller会请求channel切换。这意味着PFIFO和执行单元在不同的channel上。
每一代的channel的数量为128 on NV01-NV03, 16 on NV04-NV05, 32 on
NV10-NV3X, ??? on NV4X, 128 on NV50+。
command
存储在cache中的命令是由subchannel、method、data组成的元祖。
- subchannel: 0-7
- method: 0-0x1ffc [really 0-0x7ff] pre-GF100, 0-0x3ffc [really 0-0xfff] GF100+
- parameter: 0-0xffffffff
- submission mode [NV10+]: I or NI
每个channel有8个 subchannel ,并且有所谓的 "object"
对象关联它们。
subchannel 会标识 命令将被发送到的引擎和对象。
subchannel 没有对引擎/对象的固定分配,而是可以通过使用
method 0自由地绑定/解绑定它们。
"object" 对象是PFIFO控制引擎的各个功能部分。
单个引擎可以暴露任意数量的object类型,但大多数引擎只暴露一个。
该method选择绑定到所选subchannel的对象的单独命令,除了特殊的
method 0-0xfc,它们会被
puller直接执行,忽略绑定对象。
注意,传统上,method
被视为4字节可寻址位置,因此它们的数字被写下来乘以4:method 0x3f
因此被写为 0xfc。 这是来自PIO频道的剩余部分。
在文档中,每当提到特定的方法编号时,它将被预先乘以4,除非另有说明。
method
是介于0和0x1ffc之间能被4整除的数字,并且选择命令来执行。
可获得的method集合依赖于关联到给定subchannel的对象。 method
numbers如同内部硬件寄存器地址,因此能被4整除,这都是遗留问题。
大部分method都会直接原始的(未修改)传送到执行引擎,一些会特殊一点,直接被PFIFO处理:
- 0x0000: 绑定对象到subchannel
- 0x0004-0x00fc:被PFIFO保留使用的method,从不传递给执行引擎。
- 0x0180-0x01fc:传递给执行引擎的method。
提交给method的数据值是32位,依据method来转义。
parameter 是随该
method一起使用的任意32位值。
如果通过增加DMA数据包提交命令,则提交模式
submission mode 为 I;
如果不通过增加数据包提交命令,则 submission mode 为
NI 。
实际上在提交PGRAPH命令时,该信息存储在CACHE中以进行某些优化。
在DMA puller 和 引擎专用文档中详细描述了 method execution。
在NV1A 前,PFIFO以小端存储 little-endian 。
NV1A引入了 big-endian模式,它影响 pushbuffer / IB读取和信号量。
在 NV1A:G80 卡上,可以通过 big_endian标志为每个通道选择字节序。
在G80 +卡上,PFIFO字节顺序是一个全局开关。
The pusher
DMA 模式在 NV04+ 支持。 用户通过所谓的 USER MMIO
区域提交方法,从 NV01-NV4X 的0x800000开始,NV50 +的0xc00000。
这个区域是每个通道channel的子区域的一个很大的数组。
单个通道的大小:在NV01-NV3X上的大小为0x10000,在NV4X上的大小为0x1000,在NV50
+上的大小为0x2000。
每个通道区域应该被用户程序直接映射以提交命令。
NV03引入了DMA
mode,其中PFIFO自己从内存中获取命令,而不是手动戳它们。
NV03和NV04仅支持从PCI/AGP内存中获取命令,NV05及更高版本也支持从VRAM中获取它们。
在NV03上,没有实际的DMA mode,
相反,必须手动将PFIFO切换到正确的channel,将DMA寄存器设置为指向命令缓冲区(command
buffer),开启启动寄存器,然后等待完成。
NV03命令缓冲区由 "数据包packet"
组成,包括32位数据包标头header和一系列32位数据值data。
header 包括起始method地址,子通道subchannel和数据计数data count。
随后的数据计数data count words字将被戳入顺序方法,此顺序method
从包头packet header中给出的方法开始。
一次启动可以提交多个数据包。
在NV04上,旧的DMA被废弃,并引入了新的DMA模式。
现在可以按通道选择DMA/PIO模式。
在DMA模式下,有每个通道的 DMA_PUT 和 DMA_GET
寄存器。
DMA_GET 表示GPU在命令缓冲区中的当前位置,
DMA_PUT 表示其结束位置。
每当 DMA_PUT!= DMA_GET
,并且PFIFO有一些时间时,它将自动切换到给定通道并从 DMA_GET
地址读取命令,将其递增直到它到达 DMA_PUT 。
命令缓冲区可以存储 NV03 上的数据包,以及全新的跳转命令(将
DMA_GET 移动到另一个地方)。
DMA_PUT 和 DMA_GET
寄存器可通过USER区域访问,提交命令的常用方法是使用带有命令的环形缓冲区
ring buffer ,在当前结束位置之后写入新命令,递增
DMA_PUT 以使GPU读取它们。
当接近环形缓冲区的末尾时,插入一个返回其开头的跳转命令。
随后的显卡为 pusher 增加了更多功能。
在NV10
+上,引入了一种新的非增加数据包类型,其行为类似于原始NV03数据包,但它不是写入顺序方法,而是将所有数据值戳入单个方法method。
在NV11 +上,添加了call + return命令。
>NV40+ have a conditional command that disables method submission if
a mask given in the command AND mask stored in a PFIFO register
evaluates to 0, used for selecting a single card for a portion of the
command buffer in SLI config. NV50+ Has a new non-increasing packet
format that allows much more data values to be submitted in a single
piece
如果存储在PFIFO寄存器中的命令AND掩码中给出的掩码评估为0,则 NV40+ 具有禁用方法提交的条件命令,用于为SLI配置中的命令缓冲区的一部分选择单个卡。 NV50 +具有新的非增加数据包格式,允许在单个部分中提交更多数据值。
NV50还引入了全新的间接DMA模式。
在此模式下,命令缓冲区由一个特殊的间接缓冲区
indirect buffer 指定,而不是通过 DMA_GET /
DMA_PUT和跳转jump/调用call/返回return 命令进行控制。
这个IB缓冲区是(地址,字数)元组的环形缓冲区,由 IB_GET /
IB_PUT 寄存器控制,像旧的 DMA_GET /
DMA_PUT
寄存器,但不需要跳转命令就可以隐蔽地重新开始。
这种新模式与新的非增加数据包类型相结合,允许直接通过PFIFO提交大的原始数据块,方法是将数据包标头放在第一个IB插槽引用的一个内存区域中,并将下一个IB插槽设置为
直接指向提交的数据。
The puller
puller 的任务是从缓存中获取
命令(子通道,方法,数据元组)并使它们执行。
对于大多数方法method,特别是 0x0100-0x017c 和
0x0200-0x1ffc
范围,这涉及将元组直接提交给相关的执行引擎,但其他方法需要更多关注。
首先,有一个“FIFO object” FIFO对象 的概念。
FIFO对象是驻留在 NV03-NV4X 卡上的 RAMIN 中以及 NV50+
上的 channel通道区域中的小块内存。
FIFO对象由所谓的 句柄handle
指定,这些句柄是任意的32位标识符。
句柄通过称为 RAMHT 的大哈希表映射到所谓的上下文。
上下文驻留在 RAMHT 中,是一个32位字。
每个channel对应一个对象:在NV50之前,对象的通道ID是上下文的一部分。
在NV50+上,频道有单独的RAMHT。
在NV01上,对象的唯一类型是图形对象 graph objects。
这些是与PFIFO子通道绑定的东西。
上下文 context 包括
引擎类型[软件或PGRAPH],对象类型[供PGRAPH使用],以及一些简单的设置,如用于渲染的颜色格式。
当前绑定的子通道的上下文存储在PFIFO或RAMFC中,并且还传递给绑定到子通道的PGRAPH。
NV03的工作方式类似,增加了以下内容:将渲染设置移动到全新的实例内存(the instance memory is RAMIN for pre-G80 GPUs, and the channel structure for G80+ GPUs.),而上下文则包含RAMIN中的对象地址,即实例地址。
NV04引入了FIFO对象的一个新的子类,即 DMA对象。
DMA对象并不意味着绑定到子通道,而是表示PGRAPH或其他引擎可以根据用户命令访问的内存区域。
方法范围 0x0180-0x01fc
保留用于将对象句柄作为数据的方法,无论是DMA对象还是图形对象。
由于PGRAPH和其他执行引擎不知道RAMHT和对象句柄,PFIFO puller
在进一步提交命令之前执行 handle->instance转换。
此外,对象类型object type 现在是实例内存的一部分,称为
对象类 object class
,而RAMHT上下文仅包含对象的实例地址和引擎选择器。
PFIFO不再关心对象类型,而是由执行引擎来读取它并对其进行操作。
因此puller如何工作......在NV01和NV03上,在满足 method 0时,puller
将在 RAMHT 中查找数据作为对象句柄 object
handle,将上下文存储在每个子通道CTX寄存器中,并告诉执行引擎新的上下文。
在满足任何其他方法时,puller
将其发送到相关CTX寄存器选择的任何引擎。
可用的引擎是 SOFTWARE 和 PGRAPH。
当引擎是SOFTWARE时,“submission”涉及产生 CACHE_ERROR
中断并等待CPU处理这种情况。
在 NV04+
上,CTX寄存器消失了,PFIFO存储的唯一信息是每个子通道绑定的引擎。
实际 object 将由engine本身记录。
当遇到 method 0时,在RAMHT中查找参数,引擎被适当地更改,并且实例地址作为
method 0 被发送到相关的执行引擎。
当遇到范围0x180-0x1fc中的方法method时,也查找param并且
在提交给执行引擎之前,数据被实例地址替换。
其他0x100-0x1ffc method 也提交。
0x4-0xfc方法很特殊,由puller本身处理。
请注意,pusher 将拒绝推送puller不知道的0x4-0xfc方法。
在NV01-NV05上,从puller到engine引擎的命令逐一提交 one by one。
在NV10+上,如果两个命令都采用相同的方法,或者如果它们采用顺序的两种方法,则可以成对提交。
Pause/unpause the PFIFO
NV50 & NVC0
- 暂停
暂停PFIFO是通过将寄存器 NV50_PFIFO_FREEZE(0x2504) 的
ENABLE(位0)位 变1来完成的。
- 等待暂停
然后,需要等待PFIFO冻结。
这是通过忙于等待 NV50_PFIFO_FREEZE(0x2504) 的
FROZEN(第4位)位变为1来完成的。
- 取消暂停
通过将寄存器 NV50_PFIFO_FREEZE(0x2504)的
ENABLE(位0) 位设变为0来完成取消暂停。
- 等待未暂停
这是通过忙于等待 NV50_PFIFO_FREEZE(0x2504) 的
FROZEN(第4位)变为0来完成的。
PFIFO - The command submission engine FIFO overview Puller - handling of submitted commands by FIFO¶